
Accidentally building a GitHub Parasite
Solving one problem at a time, until GitHub became my entire backend

TLDR; A small project to build a web viewer for OpenSCAD files on GitHub snowballed into a serverless customizer, library, discussion platform, and CLI package manager running for free on GitHub’s infrastructure.
I was recently reading about the amazing work by a team at MIT in 2018 on the “Inverse CSG” problem. They developed an algorithm for automatically translating 3D models into parametric OpenSCAD models, and in the process produced a large collection of .scad files.
I followed the link to the GitHub repo, hoping to be able to see the 3D models directly within the browser, like .STL files:
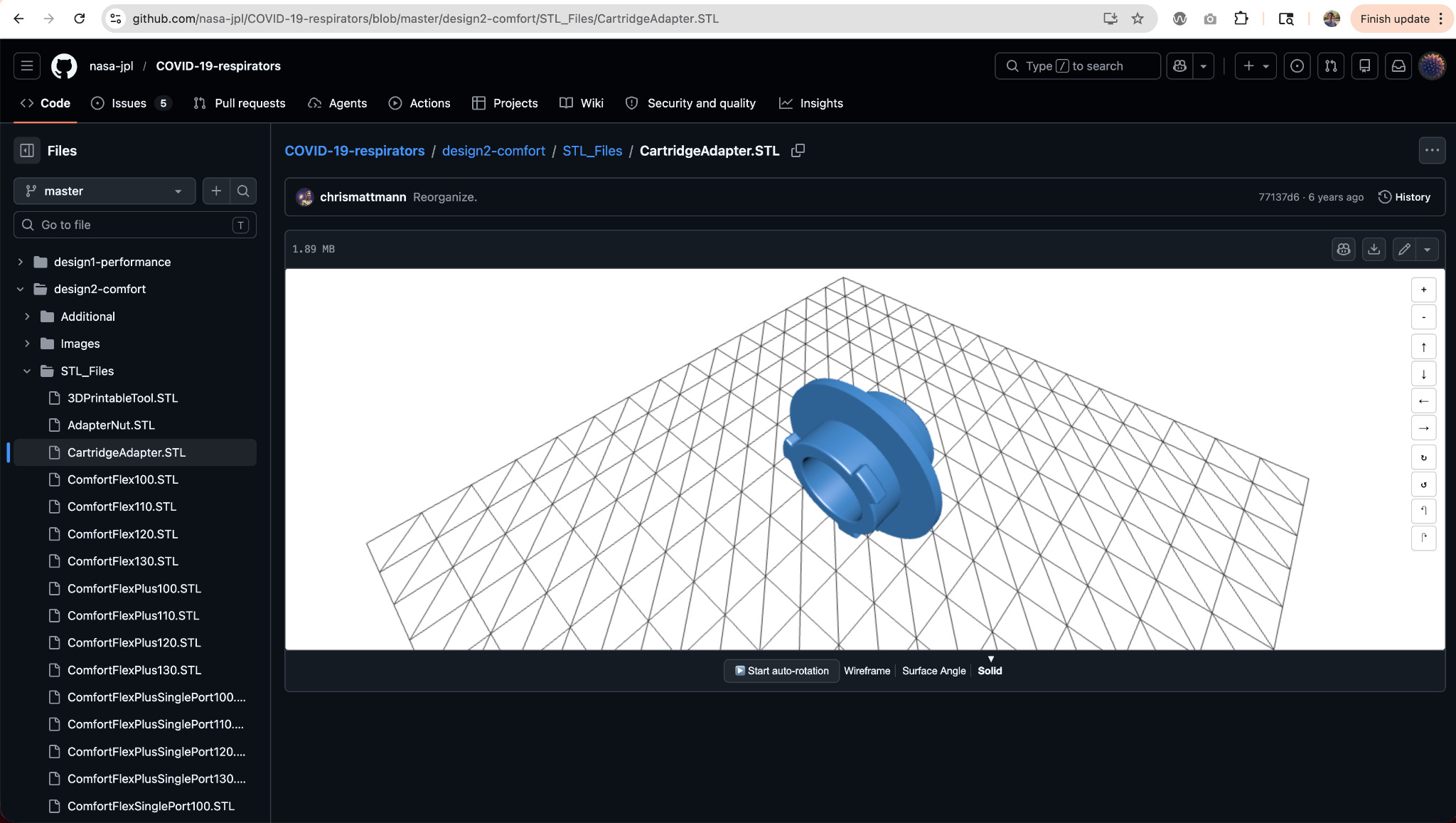
Screenshot of the .STL 3D model visualizer integrated into GitHub
But instead, I saw the OpenSCAD code:
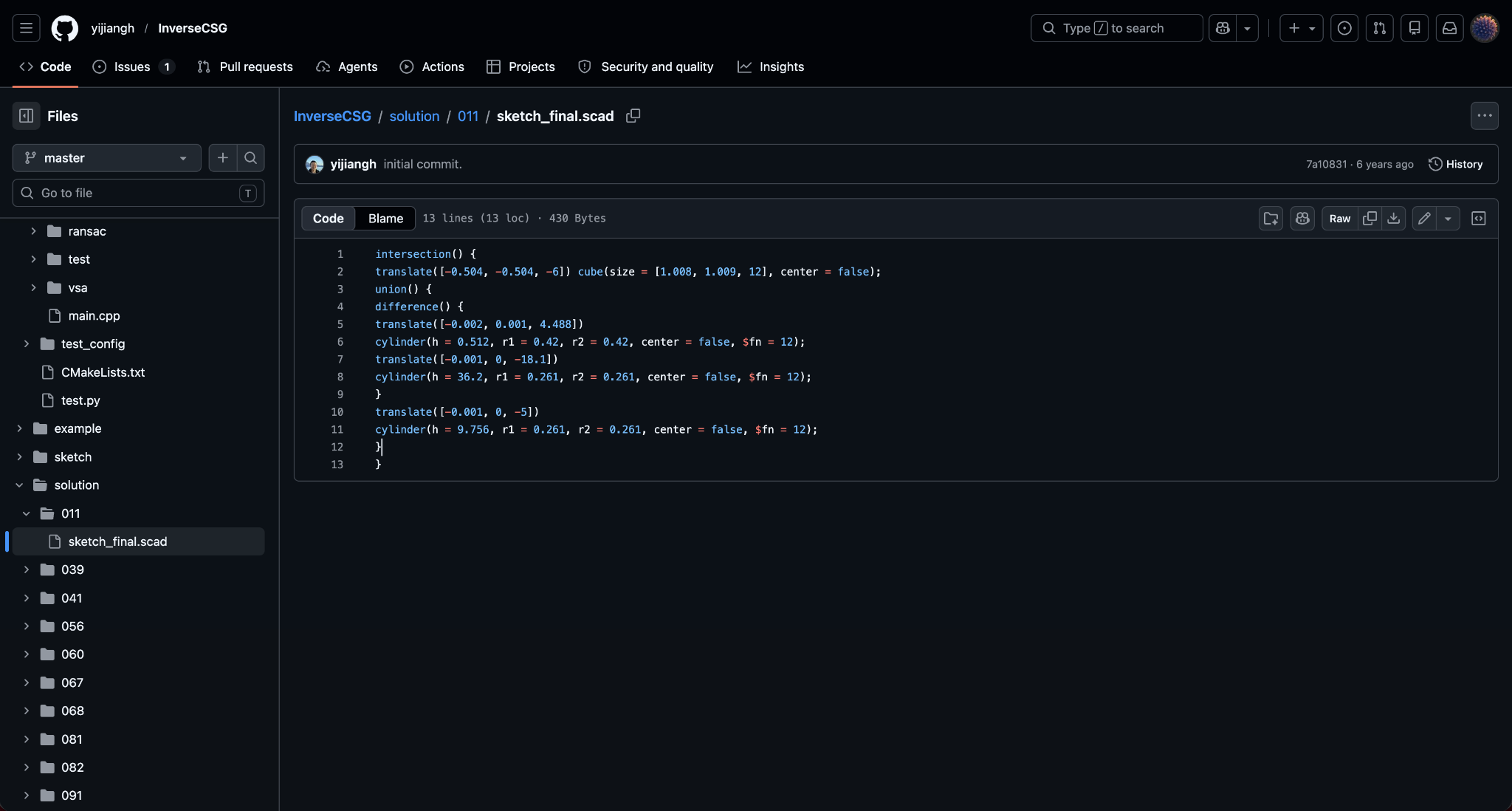
Screenshot of a .scad file on GitHub
This is what I expected to see, but I couldn't help but be slightly disappointed. I wanted an easy way to visualize the objects represented by the code so I could see the results of the team’s work myself.
OpenSCAD
OpenSCAD is a declarative parametric modeling format in which 3D models are represented as code. In order to view the 3D object defined by a .scad file, users have to download and compile the code. There’s no official OpenSCAD mobile application, so there isn’t a great way to compile and view models on a phone. A couple of browser-based editors exist like the Seasick openscad-web-gui and OpenSCAD Playground and openscad.cloud, but they all lack support for dependency resolution, and don’t allow for viewing models from GitHub.
So I forked openscad.cloud, a serverless web-assembly scad viewer in the browser, and added URL-based fetching and parsing to enable users to view scads from arbitrary GitHub URLs on the page.
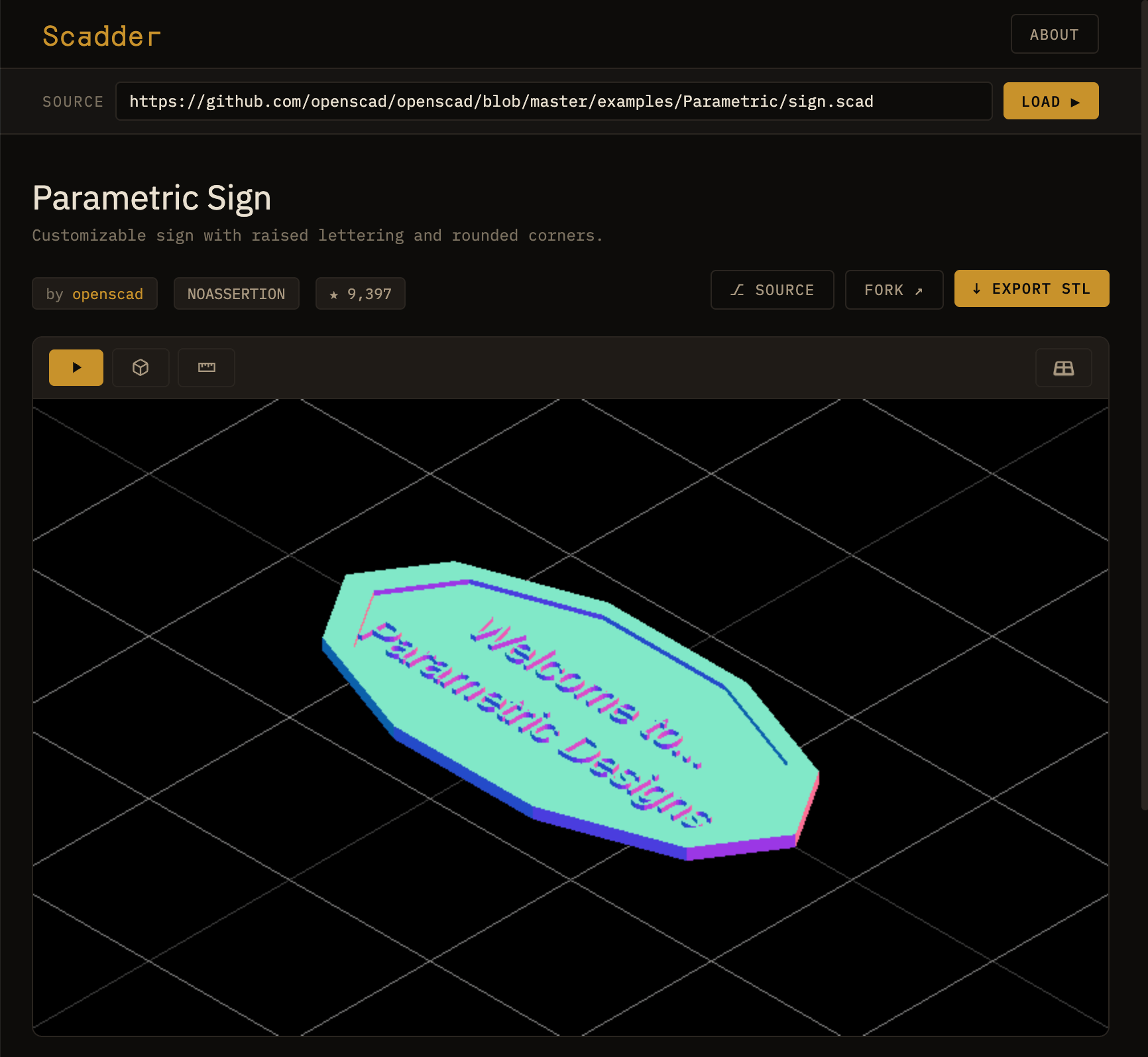
Screenshot of the 3D model viewer at scadder.dev
The rest of the system naturally flowed as a consequence of that architecture. Once the ball got rolling, I couldn’t stop it.
I grabbed some URLs of some .scads on GitHub, and pasted them into the tool. Right off the bat, I noticed that about 40% of the models that I tried viewing returned an empty scene and a console error:
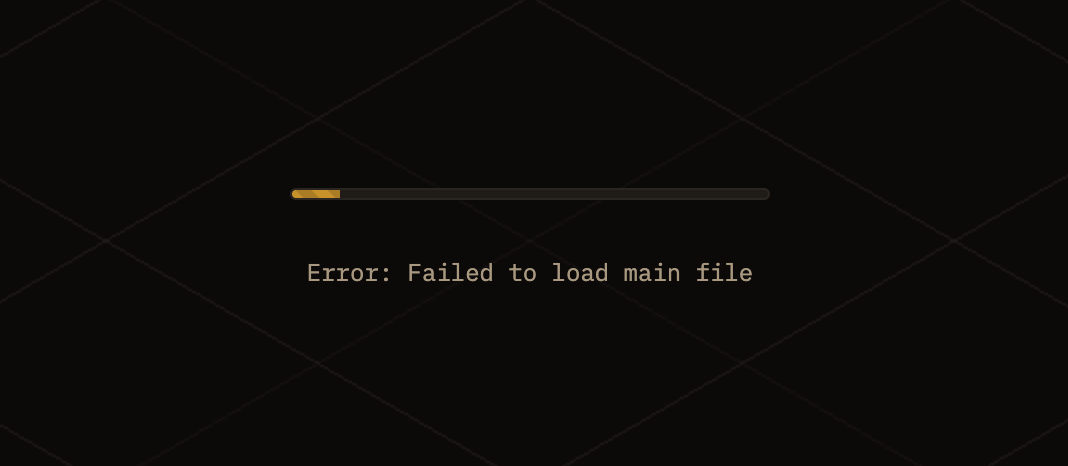
Screenshot of the error displayed when a .scad fails to load
Looking further into the errors, I noticed a repeating pattern. Many .scad files were failing to render because they were referencing other scads that hadn’t been pulled in. The fix for this was to try reading the .scad files and finding the required files on the same server, and automatically pulling those in too. It turned out that in most cases, the dependencies could be reliably discovered and pulled in with a script.
Open Source Hardware
People don’t tend to pass around solutions to common problems in the open source hardware community as frequently as they do in software. The culture is different. It tends to be common for people to redesign solutions to problems from scratch for each project instead of reuse existing designs. Vetted libraries of high quality designs for reusable, extensible mechanical components are rare, and I wanted to understand why.
Over time I realized that parametric modeling formats are like source code for 3D models. The parametric file contains the human-readable mappings between parameters and geometric features of models, and the .STL files they produce are like compiled binaries. I started to think that the lack of a widely used open parametric modeling format was a major reason behind the lack of a culture of 3D designers borrowing from one another. Formats like .f3d make parametric models feel opaque because they can’t be diffed in repos, or visualized outside of heavy native software like Fusion. But open parametric formats like OpenSCAD can. It started to become clear that the tools I use for code version control would work for OpenSCAD models too, because they’re just code. If .scad models were easier to work with, maybe people would use them more frequently, and we’d see more community libraries of 3D components.
The Model Library
With this system, a list of URLs is a library. Over time, it became clear that a simple directory-style list (like a library.json file) satisfied my need for a model collection that could be displayed on the page. When a user clicks on a model, the system loads it from the given URL and compiles it in the browser.
As I thought about how to support thumbnail images for the library, I realized something amazing. I could use GitHub Actions to automatically monitor for changes to my library.json file, spin up a headless browser running a version of my page, let the model compile and render using my viewer, then take a screenshot of the model in the headless browser and commit it back to my repo as a thumbnail. No server necessary, other than the one provided for free by GitHub. The repo itself became the database for the library thumbnails and the library.json file.
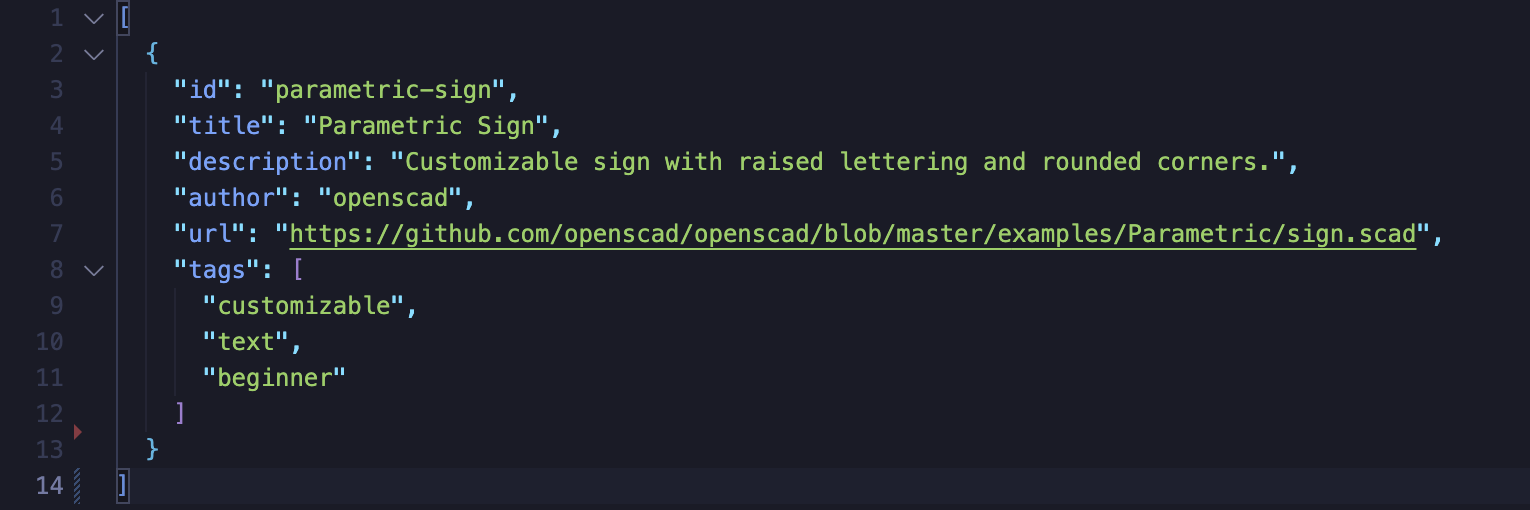
Screenshot of the library.json file
Suddenly the site became a hub linking to models from dozens of projects, not just a way to visualize a given file. And it would never cost a cent to run, as long as GitHub pages and public repos remained free.
OpenSCAD has a “customizer” standard that allows parameters to be displayed as editable fields. I was able to piggyback on that, and show the same fields that would be available in the native editor.
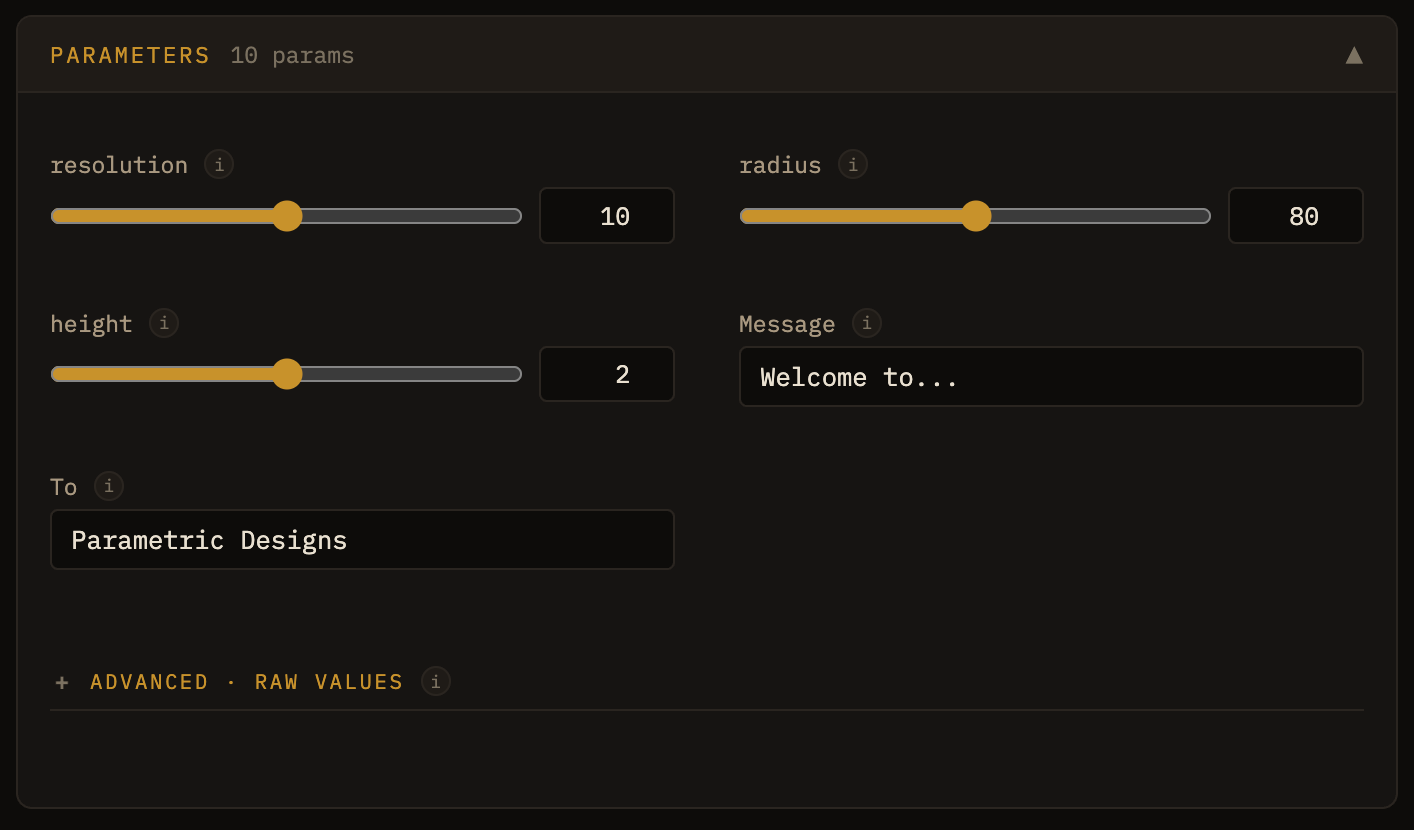
Screenshot of the inputs for dynamic parameters that are parsed from .scad files
Throughout the project, I was entertaining myself with the puzzle of how to keep the project costing $0 in perpetuity. Multiple times, I ran into apparent walls in the architectural design process, and ended up unexpectedly finding a way to accomplish my goals with free infrastructure.
For example, the natural instinct with a project like this is to implement a user management system, so people could save their work, share models with friends, and leave comments. I ended up finding a way to serialize all parameter changes to the URL instead, so users could save and share their work via the URL. At one point I wanted to enable direct editing of the scads themselves, so I compressed the diff itself, and serialized that to the URL, enabling users to replace the entire file with dozens of lines of custom scad code, and share it as a URL, with no backend whatsoever.
I wanted to enable people to comment on models, but thought that it would be impossible without paying for a Discus server, moderating it, etc. That’s when I learned about Giscus. Turns out, I could hijack the discussion section for my repo, and display that on my page instead. If I used the model URLs as an index for each discussion thread, I could enable users to discuss any model at any URL. The comments will always be there, as long as GitHub is running and the repo is public. So now I had a system capable of hosting a comment section for any 3D model at any URL on the internet, for free in perpetuity.
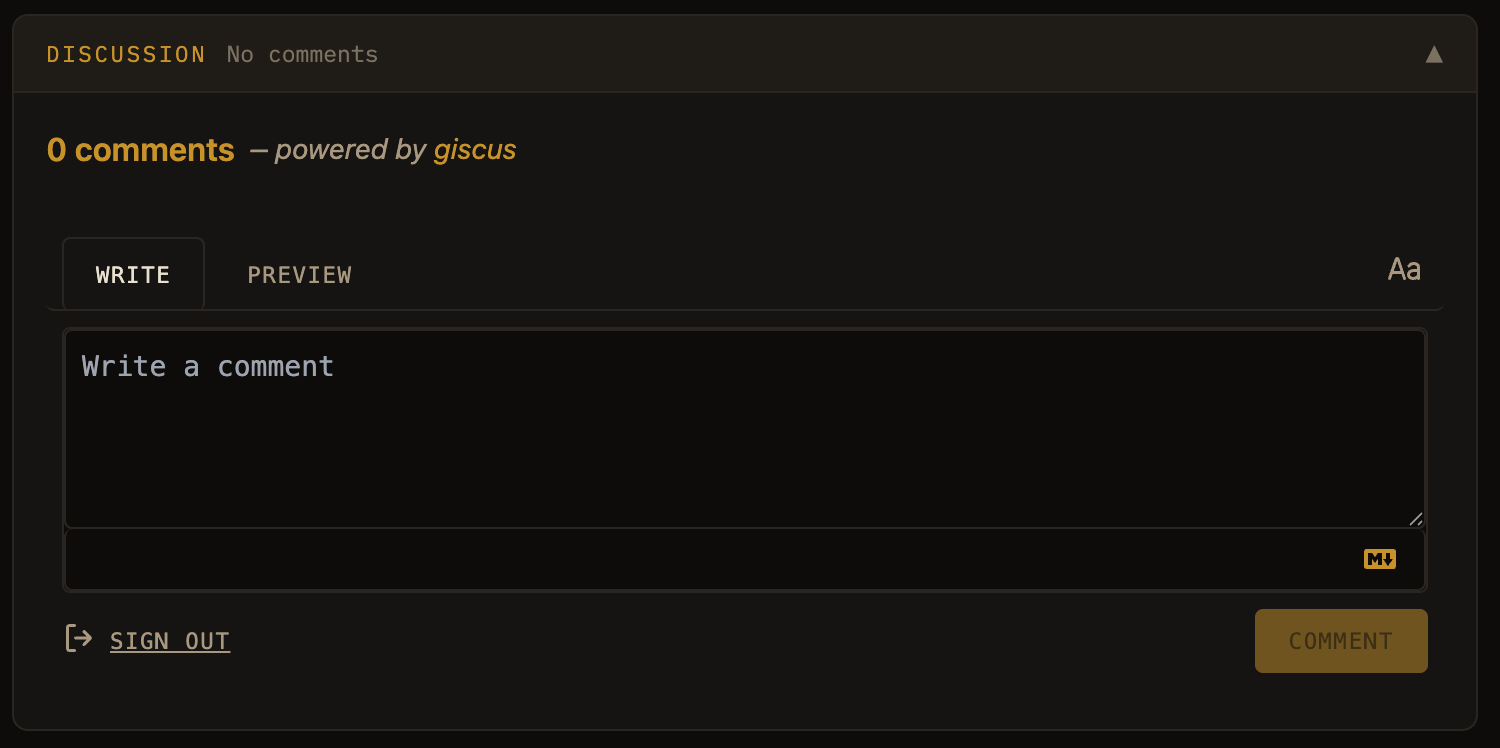
Screenshot of a Giscus comment section for a .scad file
URLs + Crawler = Dependency Manager
The OpenSCAD community has been looking for years for a way to make it easier for people to pull in models and manage dependencies on their local machines. Since I had the recursive dependency crawler and the library of .scad URLs on GitHub, it clicked that I had all of the components for a local dependency manager for OpenSCAD. Instead of instructing the crawler to output to a virtual file system, I just had to point it at my local filesystem instead.
So I built a little CLI tool on top of the web crawler, and released it as an NPM package. In order to support deterministic builds, I added a custom lockfile json that specifies the commit hashes associated with the specific versions of the files that were pulled in. It takes advantage of the fact that GitHub allows us to pull files from specific commits, so if the owner of a repository updates their repo after someone installs a file from it using Scadder, the changes won’t break the project built on top of the old version.
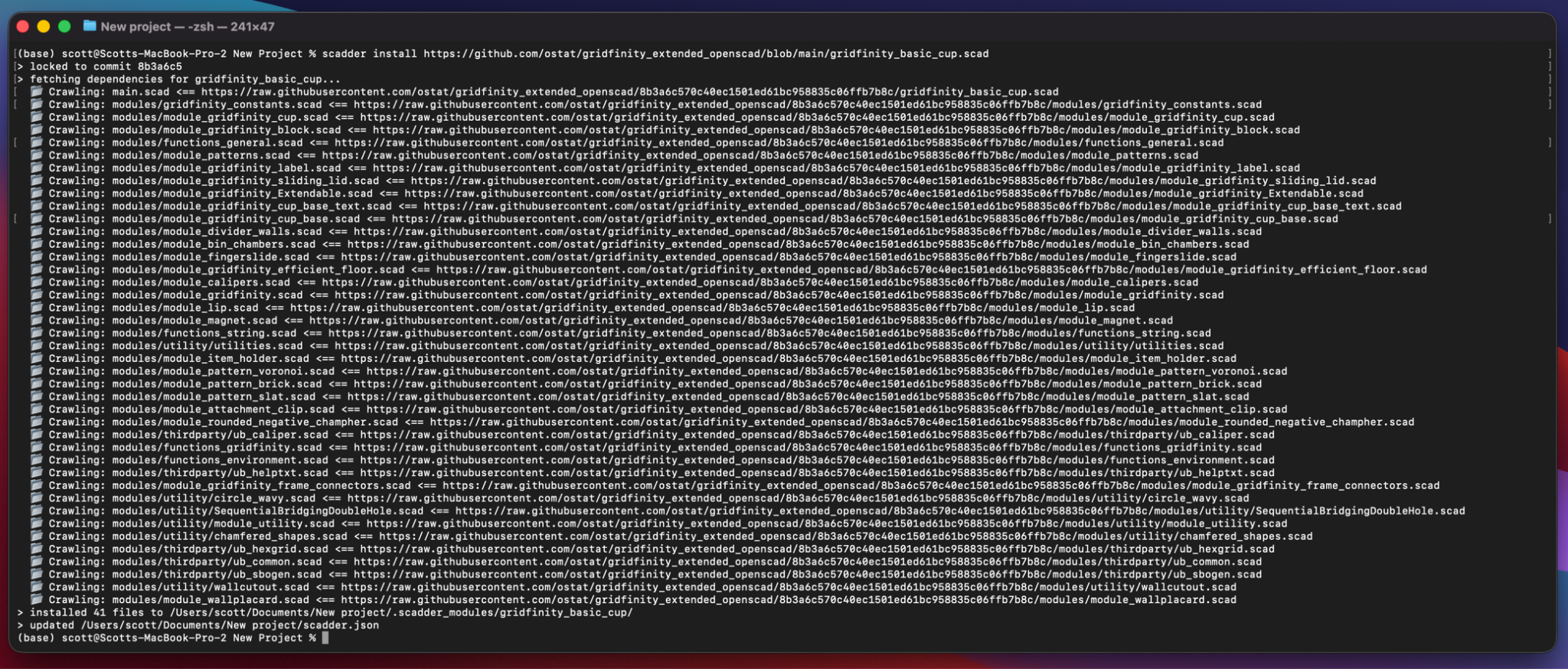
Screenshot of the CLI tool fetching 41 dependencies for a Gridfinity bin model
I ran into a problem when it came to monolithic global libraries like BOSL2. Those are installed in a Libraries folder outside of the project directory, and given OpenSCAD’s flat namespacing, it isn’t possible to pull multiple versions of those global libraries into a project at one time. Whichever version was pulled in last overwrites the previous version(s). So the best I could do was loudly inform the user if they’re attempting to install a model that requires a global dependency, and prompt them to install it. My tool offers a way to install the latest stable version from GitHub, but it’s up to the user to include a flag when running the install command to pull in the library.
Success?
The zero-cost constraint led to some interesting and unexpected ways to implement the functionality I wanted without a backend server. But at the end of the day, I’d basically just built a frontend for GitHub. Everything from the library, to the CI/CD, the actions pipeline, the site hosting, the discussion pages, and the models themselves all live on GitHub. Which is kind of appropriate, given the open-source soul of OpenSCAD, and the open nature of the models people make with it.
Hardware still lags behind software when it comes to composability. 3D designers are still modeling standard mechanical components from scratch for every project, passing around zip files, manually tracking dependencies. A true open-source hardware ecosystem, where physical objects are as easy to import, version-lock, and extend as any npm package, is still mostly theoretical. Scadder is one small, weird, serverless step in that direction. Built on a platform it doesn’t own, costing nothing, doing things GitHub probably didn’t intend to support. Feels about right.